Decían que iba a llover y no ha llovido.
Mi app siempre acierta.
Hablemos de predicción del tiempo: una cuestión matemática basada en datos que supone un reto diario debido a todas las variables que entran en juego: desde la simple precipitación en una localidad hasta la ruta que seguirán los huracanes.
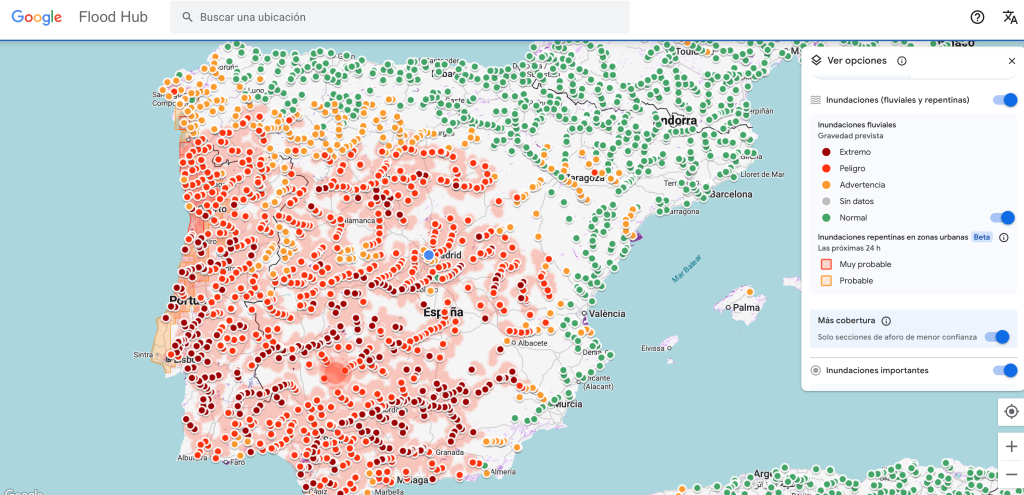
Recientemente, me he encontrado con un proyecto de Google para predecir inundaciones en cualquier punto del mundo utilizando un modelo hidrológico.
No es el primer modelo utilizado para detectar inundaciones, la Unión Europea con ayuda de la red Copernicus ya tiene su sistema GLOFAS para detectar este tipo de camios.

Google describe su modelo de pronóstico hidrológico usado en Flood Forecasting, basado en aprendizaje automático (LSTM) para predecir el caudal de ríos con hasta 7 días de antelación, de forma probabilística.
¿Cómo funciona el modelo?
Google ha desarrollado un sistema de pronóstico hidrológico basado en inteligencia artificial cuyo objetivo es predecir el caudal de los ríos y, a partir de él, anticipar inundaciones con hasta 7 días de antelación. A diferencia de los modelos hidrológicos clásicos, este sistema se apoya en aprendizaje automático y produce predicciones probabilísticas, no valores únicos.
El modelo no predice directamente “inundaciones”, sino el caudal diario del río en cada tramo:
- Primero estima el flujo en mm/día normalizados por cuenca hidrografíca
- Luego lo convierte a caudal volumétrico (m³/s)
Para cada tramo de río y para cada día del horizonte de predicción, el modelo calcula una distribución de probabilidad del caudal.
El valor que suele mostrarse como pronóstico principal es la mediana, pero internamente el sistema conserva la incertidumbre completa.
Aprendizaje automatico
Los modelos hidrológicos tradicionales se basan en ecuaciones físicas (escorrentía, infiltración, evapotranspiración…) y requieren de ajustes manuales.
El problema es, que para medir estos datos y hacer el input, tenemos que tener lo básico: estaciones de medición. Aquí esta el principal problema: no hay estaciones de medición en cada esquina del planeta.
Y es donde entra el aprendizaje automático aprendiendo patrones comunes entre miles de cuencas hidrográficas, y aplicando esos patrones a otros ríos o zonas con características similares.

¿De dónde obtiene los datos?
El sistema combina tres fuentes de datos principales:
Características fijas de la cuenca
Estos datos no cambian en el tiempo -no a nuestro nivel geografico-, de modo que se recogen los datos del tipo de suelo, uso, cobertura vegetal, clima medio o la influencia humana.
Estos son obtenidos de HydroATLAS y se agregan los datos por cada cuenca, obteniendo medias, máximos, medianas. . .
Histórico de meteorología
El modelo usa aproximadamente un año de datos meteorológicos para establecer un munto del sistema hidrológico antes de emitir un pronóstico.
Meteorología prevista
Incluye múltiples fuentes desde el Centro Europeo de Previsiones Meteorológicas a Plazo Medio (ECMWF), satélites de la NASA o pluviométros.
El modelo obtiene y combina estos y otros datos, ajustando el input para la cuenca determinada.
Los datos son obtenidos desde más de 16.000 estaciones de todo el mundo, con un histórico desde 1980.
¿Cómo funciona por dentro?
El núcleo del sistema es una red de redes neuronales recurrentes -o LSTM-, diseñada para trabajar con series temporales.
De manera sencilla, cada día el modelo lee la meteorología teniendo en cuenta el estado de la cuenca. En base a esos datos, decide qué información del histórico conserva, qué información no tiene en cuenta y cómo actualizar el estado actual.
Esto se controla mediante tres puntos: cuánto histórico se descarta, la influencia del pronóstico y el estado acutál.
¿Podemos tenerlo en cuenta?
Lo cierto es que estos modelos probabilísticos no son nuevos. Como comentaba, el GLOFAS europeo ya hace un ejercicio similar siendo uno de los referentes a nivel mundial pero estamos ante una herramienta más que nos ayuda a adelantarnos -o por lo menos conocer su impacto- antes de que se produzcan.
Según la propia documentación de Google, el modelo tiene una probabilidad estadística de acierto alta a 7 días vista incluso en sucesos extremos, siendo competitivo contra el GLOFAS a 5 días.
El modelo de Google no sustituye a estos sistemas, pero actúa como una herramienta complementaria, especialmente útil en regiones sin estaciones de medición donde ayuda a entender eventos futuros.
Un buen ejemplo de cómo los datos están ahí, solo hay que aprovecharlos.
Fuente de datos: Google Flood Hub


